Storage Space Availability As a Limiting Factor for Continuous Development
Current evidences in the continuous development show clear increasing tendency to conquer more and more sympathies of the developers’ world. Apart from reducing the cost, time, and risk of delivering incremental changes to users as was proclaimed in the famous formula by Martin Fowler, its principles and practices apparently facilitate the human power to concentrate on uninterrupted (namely, continuous) computing, i. e. creating code, building applications, designing usability and so on.
The concept “continuous development” actually encompasses several forms of the development process, which are integration, delivery, and deployment, each preceded with determinant “continuous” (see Fig. 1). Note, each stage requires conducive infrastructure environment for its seamless functioning. Have a look, for instance, at the workflow chart of continuous delivery practice provided by AWS platform.
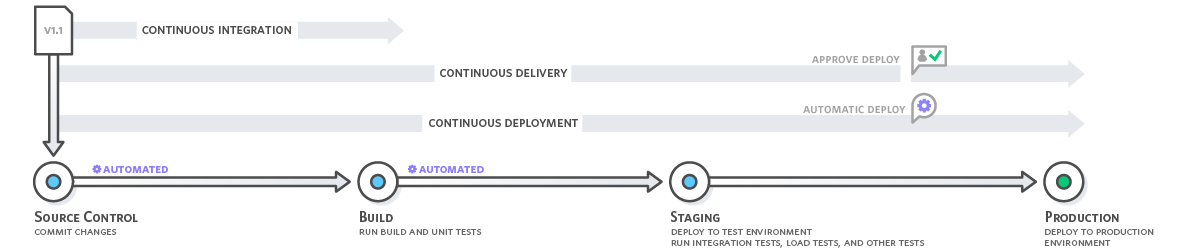
Figure 1. DevOps algorithmic design of the continuous development
"Continuous delivery automates the entire software release process. Every revision that is committed triggers an automated flow that builds, tests, and then stages the update. The final decision to deploy to a live production environment is triggered by the developer." (Amazon web services)
Now consider a number of developers based in different locations, each of them ideally needs a stand-alone instance of testing environment after every code commit. Before the emergence of tools for collaborative computing, including cloud-based implementations, it was a rather tedious and time-consuming task for a team lead to process all commits until a new feature or fix was embedded in a next software build. With the start of era of “shared” (lately evolving into continuous) development and cloud solutions, one of the main driving forces allowing countless testing facilities appears to be enough space for accommodating software updates in work before they are released into production. Hence growing significance of storage capacity.
Needless to say that storage system solution under such conditions should be scalable. However, two industrially adopted approaches to scalability allow different opportunities for the tasks in question. In case of vertical scalability, or scaled-up NAS, storage capacity can be upgraded by mounting additional systems to an existing architecture. Devices in scale-up NAS share system resources and the control function do not increase along with the storage capacity, which means that performance tends to degrade as more storage is added (see Fig. 2).
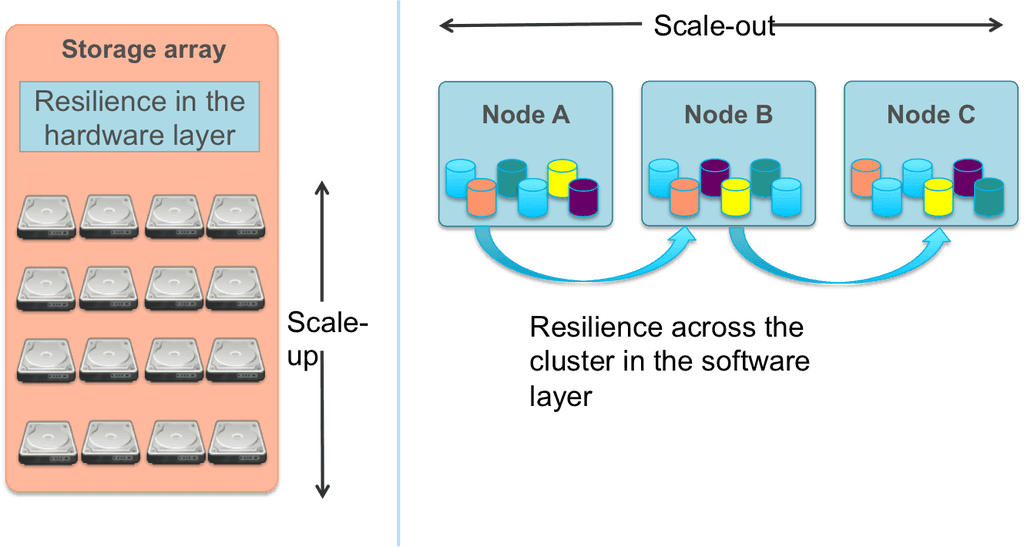
Figure 2. Scale-up vs Scale-out approaches in storage system architecture
On the contrary, in case of horizontal scalability, or scale-out NAS, the storage capacity grows with connecting additional devices united to a single logical unit, thus decreasing hierarchy of control to one unified level. For that reason, physical devices could be spread out through different geographical locations. Each device (node) includes storage capacity and may have its own processing power and data exchange bandwidth. As new resources are added, the storage capacity increases, so does the performance (see Fig. 2).
Having on-demand flexibility as its main advantage, scale-out systems are definitely more tailored for projects run within the continuous development paradigm. Therefore, such giants of IT industry as Google and Amazon since 2010 follow the policy of converting their storage systems to horizontally scalable ones. Moreover, as these companies make providing cloud computing services for global IT community their main business profile, only scale-out architecture have the capacity to overcome many shortcomings of fast tuning up additional storage devices with no effect on logical representation for clients.
Meanwhile, it is also an intellectual challenge for suppliers of scale-out NAS like NetApp, Panasas, Qumulo and others to introduce better, compared to its competitors, solution in terms of connectivity performance, integration with existing storage infrastructure, cost-effectiveness of adding first data storage units.
Mentioned aspects are being solved differently by each vendor. Interestingly, scale-out architecture allows a plethora of optimal ways to realize logical (and to some extent physical) representation of access to the storage system based on typical x86 servers. That is the reason why we are observing new relatively small vendors entering the storage systems market. For example, RCNTEC over recent few years has been working on its original scale-out Resilient Cloud Storage solution and managed to make it reasonably competitive in terms of TCO by reducing cost of capacity expansion and maintenance services as compared to the ones introduced by their renowned rivals.
One can conclude that it has not been possible without the breakthrough advantages which scale-out principle of organizing storage devices offers. To start with, let’s consider easiness of mounting additional storage unit into the existing storage system. In classical scale-up approach one needs to take into account, first, the currently utilized capacity to host more devices of a storage controller (normally, a pair of controllers being one leading, while another supplemental). Until its limit is reached, you can add new disk shelves at a relatively unaffected performance.
The different story begins when there are no more resources of a controller to accommodate additional unit of disks. This time it is a burdensome activity consisting of reconfiguring physical and logical space for storage, adding or deleting new rules of data backup and recovery, etc., which adversely affect the availability time when system is up and running.
In scale-out architectural approach, the idea is to circumvent the necessity to deal with the controller-managed storage system. In reality it means to redesign the system so that only the disk module layer is directly accessible from the client’s side, thereby eliminating controller-responsible operations from the chain of data exchange process. In so doing, low-level storage unit which is typically represented by x86 server (equivalent to a disk shelf in the scale-up NAS) plays the role of the first and the last level in the hierarchy of data flow before it is stored and/or replicated. In these servers the disk storage is tied to each node similar to Direct Attached Storage (DAS) architectures of old. Regardless of whether the disks are internal to the server chassis or an external JBOD connected by SAS, only the individual server has access to this physical server (see Fig. 3).
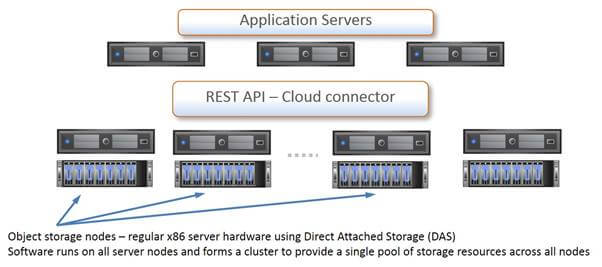
Figure 3. Overall scheme of scale-out architectural approach
Thus, the total amount of disk space expands through the addition of devices in connected arrays with their own resources. Therefore, the performance of storage system increases linearly with each added data module. The second issue resolved differently by both competing approaches is how to implement data redundancy to guarantee its safety and integrity. Scale-up NAS manages this process through RAID (Redundant Array of Inexpensive Disks). However, RAID itself is managed by a specific controller that then decides on how the storage blocks are laid out onto the drives to provide the physical drive resilience. So it is impossible to scale that system out simply by adding more controllers, every time one such event occurs it needs to be reconfigured and tested on coherence. For that reason we face a serious scalability decline when RAID is in place.
For the scale-out NAS a so called object-based storage was introduced, i.e. the data is organized as abstract units of storage called objects. Every object consists of: a) the data itself; b) an expandable amount of metadata; c) a globally unique identifier. Having object data representation, it is easy to install on the node (disk unit) the specific software enabling this standard while the data is being stored, so that all nodes can be combined into a single cluster, whereby all storage tied to each individual node is brought into a single storage pool and presented out to the user/application network as a single unified name space. As a result a user does not know on which node data is placed – it is just presented with a storage container with a Fully Qualified Domain Name (FQDN). The object storage system manages the store, retrieval, and protection of the data objects and manages the data placement across all the nodes within the cluster.
As was mentioned, RAID cannot be applied into a multi-node architecture, so a variant of it called Redundant Array of Independent Nodes (RAIN) is used for the same purpose in scale-out NAS. RAIN is known to be of two types, driven by:
- Replicas - complete copies of a data object which are distributed across multiple nodes – similar to mirroring in RAID concepts, but commonly more than just two replicas are used.
- Erasure Coding – offers similar data protection capabilities as RAID 5 and RAID 6 by creating parity for data sets in order to provide protection against failures (but without the capacity overhead of mirroring data).
Finally, to make all these horizontally scaled object-based storage components work together well, the software installed at the foundation level of the x86 servers operating system is developed.
Coming to the question of the cost of implementation of each storage system type, it significantly depends on the plans and the activity profile of a business-user. When its management is sure about the certain limits of the data stored within the company, aware of some tricks of deduplication while manipulating with data provided by top-brand controller of storage system, it may be advisable that a business opts for the scale-up solution.
But how many such businesses we can encounter nowadays on the global market? What if with the growth of business it will end up with the need to acquire one more rack of disks in its storage room? Skipping the need of allocating considerable budget to make a purchase of next cumbersome complex of storage system with fresh controllers, such a case will also require from its technical staff an activity of setting up new instance of storage space, rewriting backup and restore rules, possibly, rewiring network connections and so on, which will be reflected in degraded performance (extends idle time of the storage availability, overwhelms data throughput while performing data redundancy support operations, etc.).
Another picture is seen when a business opts for scale-out storage system, which seems to be a global trend (see Fig. 4). It can start with a small set of data units configured to maintain replication and coordinated by monitoring server machines (which are essentially based on the same hardware as servers with disks), and as consumption of storage reaches the limit of the first set, just increment another node, thus expanding the object-based cluster with no specific technical manipulations.
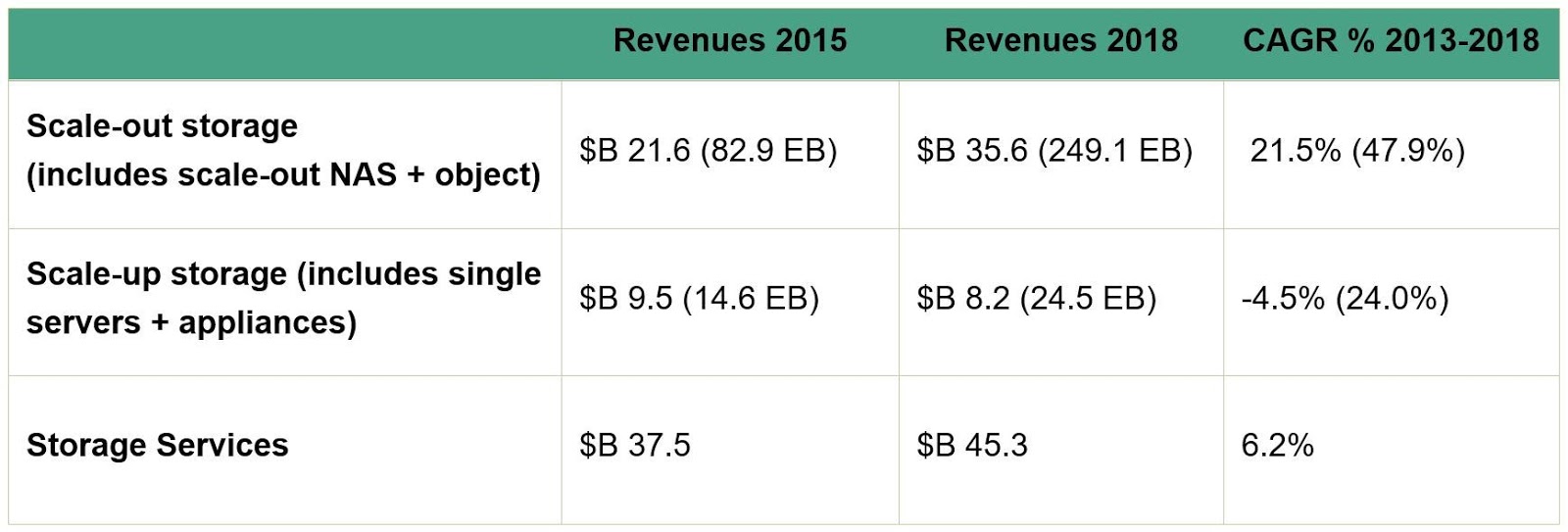
Figure 4. IDC data on scale-out storage market CAGR
Getting back to our point of maintaining favorable environment for continuous development, take as an example Amazon Web Services (AWS) platform. As it is offered throughout the world, it is reasonable to suggest that Amazon company hosts the platform in several big data centers located in different geographical areas to provide fast service for its customers. With scale-up systems in place, Amazon has to elaborate a unique estimation technique of its clients` needs growth, so that one fine day not to end up with the failure message: “The site is on the maintenance. We are working hard to resolve it. Please bear with us”. Apart from reputation implications, it can lead to profit loss due to subsequent customers’ outflow.
But do you believe that such a technique can be devised in our highly unpredictable and volatile reality? For sure, even gurus in the field of stochastic processes will not assure the deterministic success of their estimation. At the same time, why Amazon needs that sophisticated technique? Just to make sure that it will handle well in advance the storage space exhaustion when another unforeseen group of IT startups will impose exponentially increasing demands on the cloud facilities while extensively testing its frequent software releases, updates and fixes. It implies: to make purchase of new storage system stuff with some reserved disk shelves, physically allocate it in one of its data centers, integrate it into the existing pool and many other routine time-consuming operations.
Much easier way to avoid delving into sophisticated calculations of future clients’ demands in storage space, including securing enough financial funds for unanticipated situations with storage deficits, would be migration to the scale-out implementation of its NAS. This solution will help not only get rid of a fear to underestimate the clients` appetites, but also normalize company’s budget expenses in buying additional set of horizontally scalable data modules. To summarize, it is clearly understood that the successful future of current development practices will heavily depend upon the advances in the storage systems' availability and efficiency.