New Era of Software-Defined Solutions for Data Storage Industry
Software-defined storage (SDS) term has been around for a decade. However, the practical realization and customers’ awareness of it was evidenced only recently. So why software-defined storage? Apparently, the name implies something different from hardware-based storage. In fact, the reality does not let us enjoy clear differentiation, rather due to marketing efforts of leading storage system providers IT professionals need to dive into peculiarities of the related implementation levels, be it virtualization infrastructure, cloud-based computing, distributed data warehouse, etc, to be able to operationalize this notation in their every-day routine. This is because each of the mentioned levels can leverage SDS morphing of its storage management policy heavily (not to say solely) depending on specific problems IT team tries to solve.
Some examples of SDS are:
- Ceph
- Gluster
- FreeNAS
- Nexenta
- VMware Virtual SAN
All but the last solution are open-source and built on some operating system, therefore, not embedded into system level. However, there are also rare SDS flavors which are integrated into the system level, typically developed by big renowned vendors offering it as an alternative product to its main ones. Take as an example the featured solution NetApp ONTAP Select which was launched about one year ago. In its datasheet NetApp recommends to tailor its proprietary SDS services for hybrid cloud (see Fig 1).
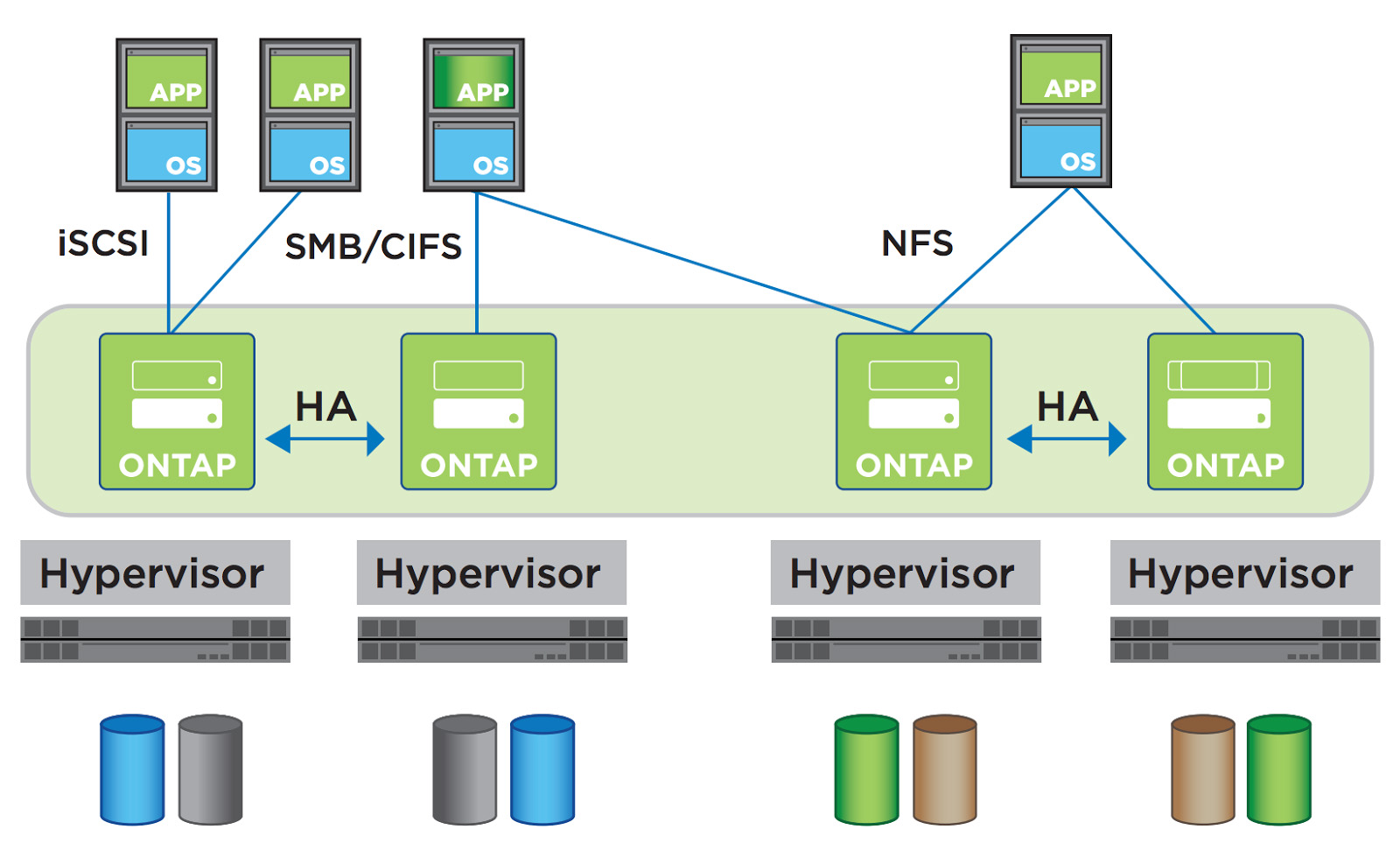
Figure 1. Four-node configuration of NetApp SDS solution built on Hypervisor
Later in the text we discover it should be installed on the VMWare hypervisors and it requires servers with Intel Xeon CPU having RAID controller to ensure local data resiliency. To put it simple, NetApp introduced the solution mounted as one more intermediary layer into the enterprise-wide cloud environment which, in turn, is made available to end-users via virtualization platform. Thus, it is nothing more than a smart bypass of collecting storage space from various (predominantly, spatially distributed) server-driven data shelves and inputting it in the appropriate format to the VMWare tier which consequently treats it as an enlarged storage cluster. Needless to say, such an approach cannot overcome the limiting bound of data throughput imposed by VMWare platform during its communication with clients.
Maybe in the situation when an enterprise faces against the disproportionally utilized storage in different data disks and realizes that additional cost of networking them altogether with SDS service implementation is less than acquiring new disk shelf/storage system, it is worth of opting for that solution.
Note, in our example we met with scale-in storage architecture (because of RAID controller existence), whereas in much more adequate real-case scenario we consider SDS when we deal with scale-out approach.
As was shown in our previous review (paste here the link to my first article), scale-out storage design is more advanced way to tackle ever-growing needs for storage space in the big data IT world. It allows clients directly access information stored on data modules. As such, the latter is subject to be virtualized as a software-defined storage (Fig. 2).
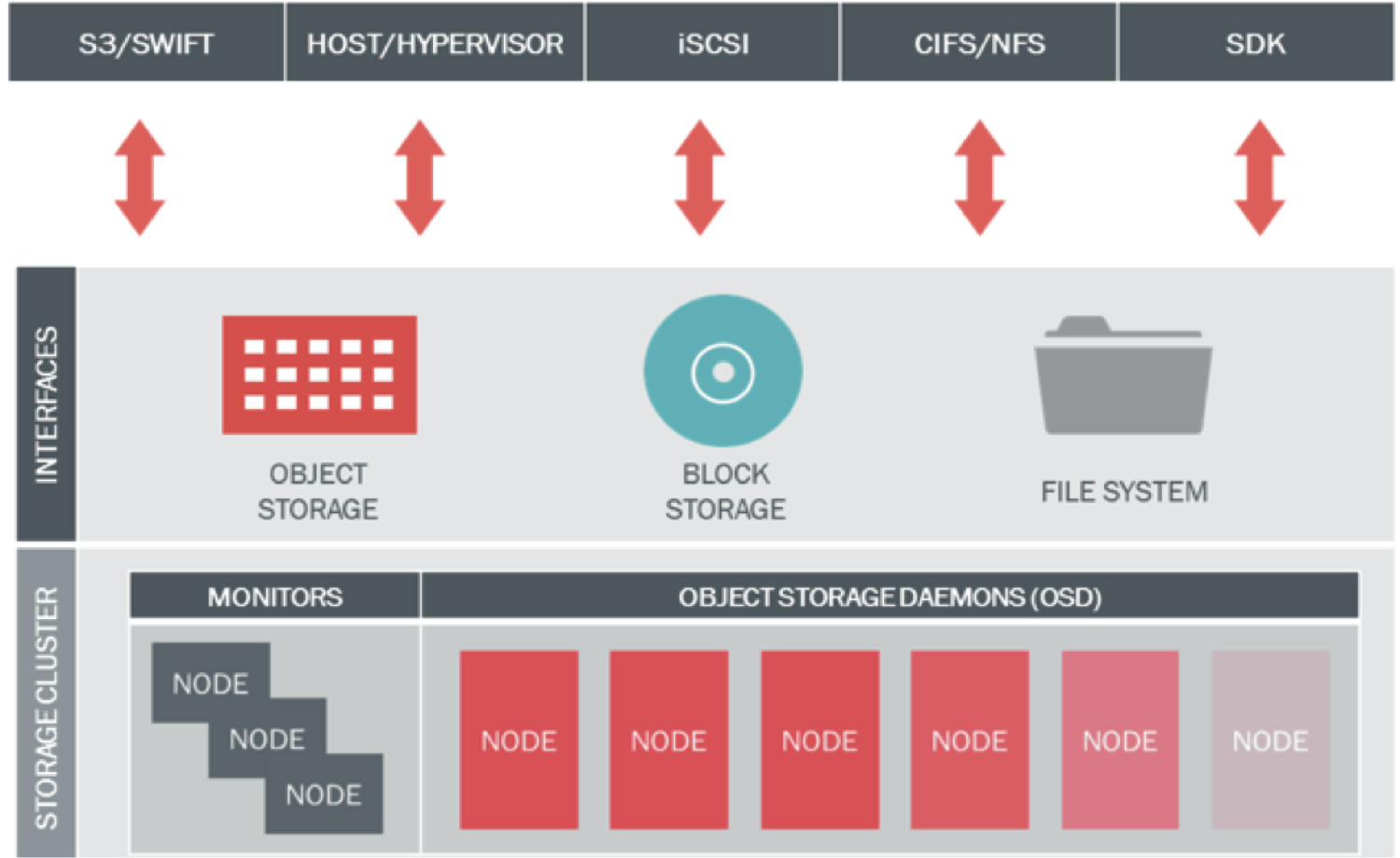
Figure 2. SDS realization in the scale-out architecture
Here SDS services (developed on top of the specific OS installed on x86 server being in our case a data module) play the true role of a main management, control and access layer, which maps file, block, and object storage so that they are available for direct queries from clients. It also takes control of the maintenance of data redundancy operations following RAIN standard policy, e.g. replications or erasure coding. The idea is not to be screened off by any other virtualization layer (indeed replacing it) on the data path between end-users and physical disk devices, thereby separating hardware stack from logical representation on the enterprise scale.
Several storage vendors who adopted scale-out approach have released software versions of storage products that were previously tied to specific hardware. Examples include Dell EMC's UnityVSA from its Unity storage array and IsilonSD Edge from the Isilon scale-out NAS system. Another example is RCNTEC with Resilient Cloud Storage, NetApp FAS Disk Shelves and Storage Media, and others.
Realization of SDS services across vendors differs. Some decided to build it on top of underlying server OS and in a virtual machine, whether on premises or in a public cloud. Others opted for providing it as a software package on a server hypervisor kernel. Some SDS products can run in a container to conserve server resources and facilitate the consistent management of container-based applications and storage services through a single container orchestration tool.
For that reason SDS concept is not defined concisely and unambiguously – a vendor would use it loosely, because by virtue of the system developers’ job he has already contributed to the expansion of SDS implementation domain with his marketed solutions.
Hardware-integrating Box-Ready Solution vs. Software-Only Version of SDS
Although SDS literally means separation from hardware, the majority of vendors is supplying their solutions as a single box-ready storage system together with the specific hardware. Obviously, by coupling its software with the certain server/disk shelf components a vendor minimizes the risk of the underlying equipment malfunctioning and maximizes its return on investment into these third-party constituents of its system. Simultaneously, it makes the overall storage system more expensive at the initial stage of ownership (it will not be such on further expansion stages as extensive growth of scale-out platform is due to adding new data modules keeping the existing coordinating, networking, monitoring infrastructure intact).
The alternative is to develop truly software-based product offering similar opportunities of storage space manipulation. It is exactly the case with mentioned earlier ONTAP Select. Below we attempt to compare pros and cons of both approaches.
Though the concept of SDS is not yet strictly defined, any SDS must be characterized by the following key features (Fig. 3):
- Automation – Simplified management that reduces the cost of maintaining the storage infrastructure. It holds for both approaches, since either of them provides tools to simplify operationalization of the storage system by encapsulating routine operations in several functions.
- Standard Interfaces – APIs for the management, provisioning and maintenance of storage devices and services.
It is the most problematic issue across the solutions, because each vendor, normally, protects his know-how technology by introducing proprietary API. In that sense software-only version of SDS does one step forward to establishing standardized API so that developers’ intellectual effort would be focused on enhancing the capabilities of interfaces in direct access to physical storage and not on designing one more not always optimal way to communicate with the same equipment. On the other side, standardization makes downsizing pressure on the revenues a vender could have received from selling his unique technology. Contrarily, customers will eventually enjoy less capital expenditures and that is where the driving force of the market will do.
This point was emphasized during Open Storage Summit EMEA 2013:
"Unlike servers, laptops and other devices the storage products I don’t think are standardized at all. I can pick 3 major vendors out there, put them next to each other, and if I open the box they will look totally different: they all got proprietary operating system, they all got the proprietary management in there. The only thing that is standardized here is the disks they are using, because there are only 3 manufacturers of disks, I believe, and one more only thing that is standardized is protocol – iSCSI, Fiber Channel, etc", - Robin Kuepers, Storage Marketing Director, Dell
However, nowadays the standardization curve finally starts to happen when it comes to storage. For a long time it stayed on what is called the proprietary technology, and all storage vendors have been acting in the proprietary space. Due to new start-ups like RCNTEC, for example, the market is changing, customers are getting much more verbal, much more louder, we see that the standardization is getting in. It is found in the area of storage data modules, which are principally based on x86 Intel server architecture. The ultimate space would be fully industry-standard solution. That means everything is open to everybody, no lock-ins, nothing is proprietary. Of course, that ideal situation is unlikely to occur because there are always specific interests of big businesses out there in the market of storage systems. Probably, vendors with their APIs and open source community with its shared base will come to one mutually beneficial point of coexistence, not so actively clashing as in case with Windows and Linux, for instance.
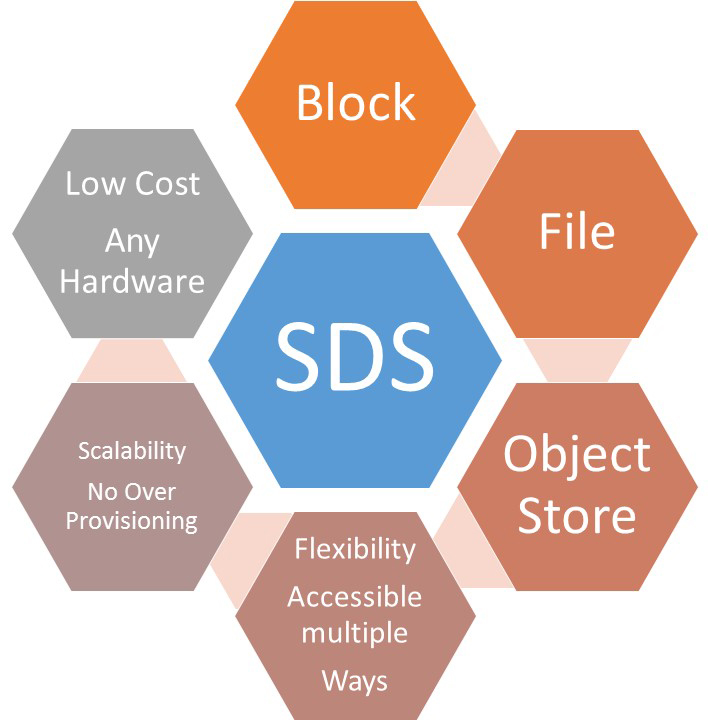
Figure 3. Outline of key advantages of SDS
- Virtualized Data Path– Block, File and/or Object interfaces that support applications written to these interfaces.
Here it differs in the number of protocols supported by each of the solution. Some provide the support for block, file, and object storage under unified management across a distributed server cluster (NexentaEdge, Resilient Cloud Storage), some support only block (iSCSI and Fibre Channel) and file (NFS and SMB) storage services (Dell EMC UnityVSA, NetApp ONTAP Select). Others concentrate on management of distributed file system running across multiple nodes (IBM SpectrumScale, Qumulo Core). Note, software-only version of SDS is bound to the virtualization platform such as VMware and is restricted by the protocols which are handled by it.
- Scalability – Seamless ability to scale the storage infrastructure without disruption to the specified availability or performance.
It is the table stakes for any storage system found on the market. The main working principle here is "pay as you grow", which allows end-users flexibly adjust their expenditures on the additional expansion data module only when the need arises. Basically, all box-ready solutions listed above satisfy the criterion of performance linear increase with adding new storage-responsible components.
In case of ONTAP Select it does not go so straightforward, because it is designed keeping hybrid cloud in mind, namely, a capability to combine heterogeneous storage systems managed by controllers and/or virtualized platforms. Therefore, it is in between scale-out and scale-in systems and does not demonstrate linear increase in performance and will be useless in case of utilizing the space on all existing disks, simply because there will be no way to redistribute it in the cloud.
- Transparency – The ability for storage consumers to monitor and manage their own storage consumption against available resources and costs.
In other words the task of budgeting for replacement of damaged disks or whole units of disks, upgrade or growth of the current datastorage becomes much clearer and easier. SDS services will take responsibility on guaranteeing data integrity and replication, thin provisioning, snapshots, autobalancing and other supportive operations over the virtual pools or clusters of enterprise-wide storage capacity.
There is no particular difference in the effectiveness of such operations between box and software-only solutions, except the first is applicable on homogenous (data modules are supplied within the box) while the latter – on heterogeneous (third-party data disks are compliant with the specifications) physical architecture.
Benefits from SDS are tangible on the data center scale
It would be wrong to say that SDS-based technology is being implemented across the most enterprises with high workload of storing data. Even though it emerged recently, businesses dealing with big data are not in a hurry in regard with deploying it on local premises. The reason why is of no secret – their volumes of data are not big enough for the old-fashioned and familiar hardware-tied storage systems to fail process them properly.
It reminds of the situation with complexity of two types of sort algorithms. In case of selection sort, the complexity is , where n is the size of the array of numbers to be sorted,
or Θ(n) = n2
in the worst-case scenario. More optimal way of sorting is based on the “divide and conquer” principle and known as merge sort, the complexity of which is
for n > 1,
or Θ(n) = n log2n
Easy to see that for small n the values of T(n) of both algorithms are close to each other, whereas for Θ(n) of merge sort is far below that of selection sort.
Similar analogy is with SDS and hardware-based storage: the cost of ownership for those companies that are not with the storage capacity hunger on regular basis is not in the favor of SDS, while for data center-like ones overwhelmed with rapid growth of virtual machines, aggregation of distributed disks in unified clusters, maintenance of data safety long-term advantages of SDS extremely outweigh its high initial cost (financial as well as administrative) of installation and deployment.